New Jersey Areas Air Quality Prediction Model Description
Training Data

The dataset used for training the air quality forecasting model is sourced from 'airquality.csv', which is a part of a comprehensive collection of atmospheric data. This data contains various features that are pertinent to air quality prediction. Before feeding it to the model, the dataset is divided into training and test sets. The training data assists the model in learning and recognizing patterns, while the test data is used to evaluate the model's accuracy. To ensure the model processes the most accurate information, the features in the dataset are normalized to a standard scale. The primary sources of this data include:
Model Structure
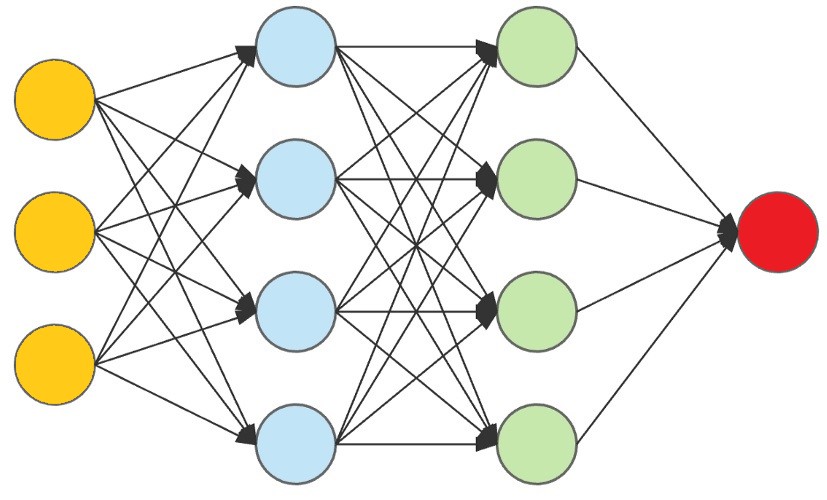
The backbone of our air quality forecasting tool is a neural network designed using TensorFlow's Keras library. This network comprises three layers:
Resulting Statistics

To ensure our model's reliability, we validate it using the reserved test data. During the training phase, the model's accuracy is continually checked against this test data, allowing us to see how well it performs on data it hasn't seen before. Additionally, to understand the relationships between different atmospheric conditions, a heatmap is generated, showcasing the correlation between each feature. But that's not all – we also employ a RandomForest classifier to discern the importance of each feature in the forecasting process. This not only helps in model refinement but also gives users insight into which factors majorly contribute to air quality variations.
As a result, our air quality forecasting model has demonstrated exceptional performance, achieving an accuracy rate of more than 89%. This accuracy rate ensures that the forecasts made by the model are reliable for assessing air quality levels.